

Overwhelming evidence of recent evolution in West Eurasians
A new paper adds to the evidence that selection favoured higher intelligence in prehistoric Europe.

Written by Emil O. W. Kirkegaard.
David Reich is the Harvard geneticist who caused a stir in 2018 when he wrote a piece for the New York Times arguing that “well-meaning people who deny the possibility of substantial biological differences among human populations are digging themselves into an indefensible position, one that will not survive the onslaught of science”. His team has just released a major new study. It has the catchy title ‘Pervasive findings of directional selection realize the promise of ancient DNA to elucidate human adaptation’.
Reich and his colleagues deserve credit for promoting true “open science” principles in ancient genomics. They have spent considerable effort collecting genomes from many studies, aggregating the data into a consistent format, and making it publicly available. Here I mean genuinely publicly available, as in literally anyone can download it without signing up or agreeing to censorship terms, having an approved academic email, or being a “bona fide” researcher. So if you are a hobbyist or you work in a different field, you too can download the data and look at some traits the researchers didn’t look at, or try an alternative method.
In their latest paper, Reich’s team took a close look at recent evolution in “West Eurasians”, which basically means the people who historically lived in Europe, Turkey and the Caucasus:

Given the large scale of the data – 8,433 genomes spread across 14,000 years – they could employ powerful methods to find the specific variants they were looking for, namely those that have changed faster than would be expected from the various migrations and population turnovers, as well as random chance. After finding hundreds of such variants, they checked what they seemed to code for to see what bundles of traits had been favoured by selection.
The simplest approach was to look at single alleles that showed particularly large changes. When they did this, they found a lot of selection for visible phenotypes like skin colour (unless the relevant alleles have some other effects that were even more important). This, obviously makes sense given what we know about contemporary West Eurasians.
In the next stage of the analysis, they aggregated the signal for many variants into a polygenic score and tracked how it had changed over time. They don’t pull any punches when it comes to the phenotypes they examined:
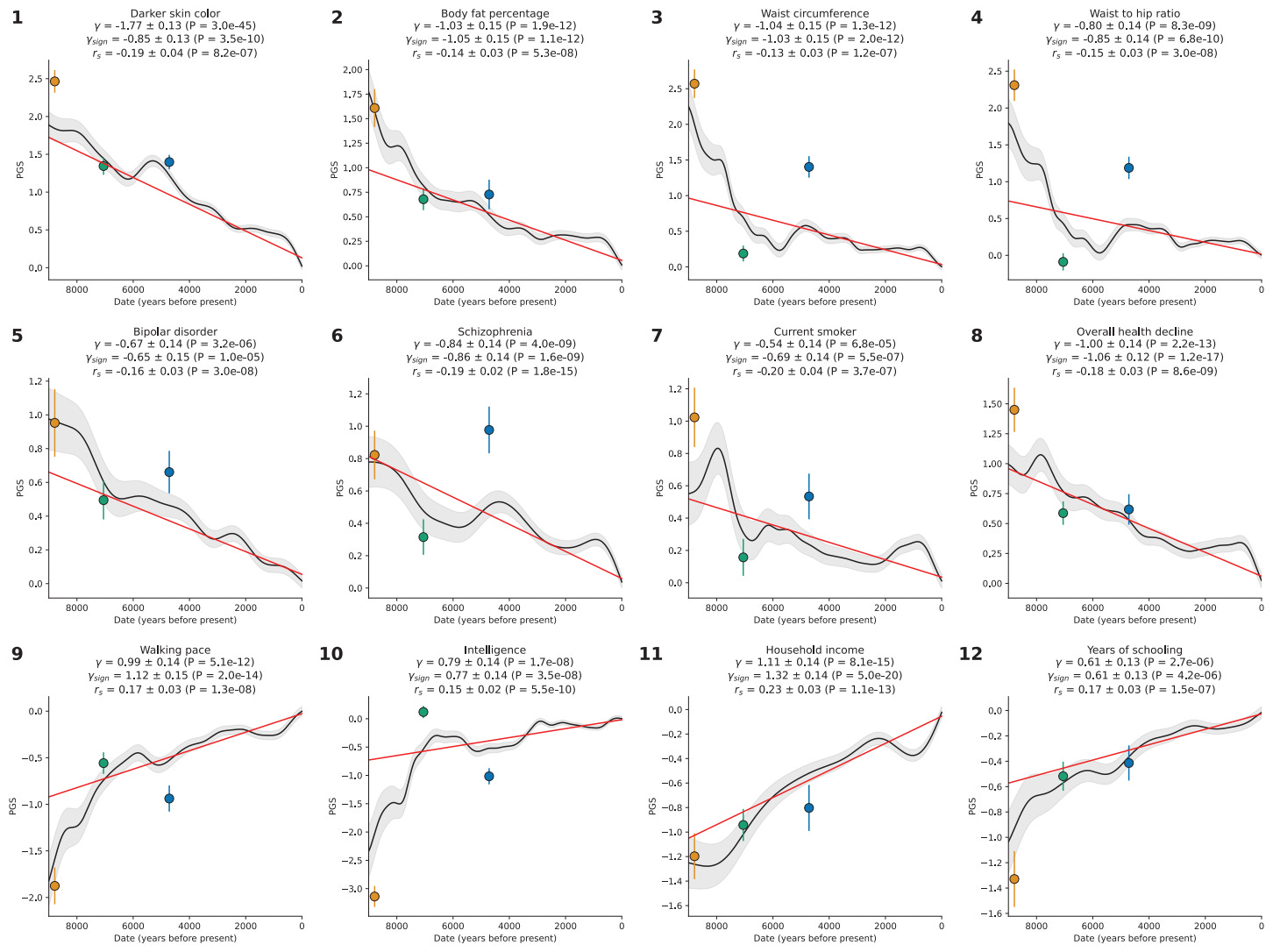
Now, West Eurasians are an admixture of three older populations, so it is informative to plot the average polygenic score for each of these populations alongside the overall trend. For example, it appears that the farmers from Anatolia (green) were markedly less prone to schizophrenia than the hunter-gatherers (orange) and the Indo-Europeans (blue). Despite the Indo-Europeans arriving with elevated schizophrenia polygenic scores, the trait was under continuous selection to be bred out.
Most interesting is that the hunter-gatherers were apparently much duller than the farmers, and even the Indo-Europeans weren’t all that impressive, despite having had great success in displacing the locals (northern European populations are about 50% descended from them). If we look at the social status polygenic scores, on the other hand, we see that the Indo-Europeans do quite well. One interpretation is that Indo-Europeans had good “non-cognitive” skills, though not particularly high intelligence. This inference is based on the idea that social status, and the associated polygenic scores, reflect a mixture of intelligence and other traits (e.g. such as being reliable, prosocial etc.). So if one removes the intelligence part, the left-over part reflects these other “social status-causing” traits.
The idea was previously applied in a “GWAS-by-subtraction” published in 2021. Scott Alexander put a positive spin on the findings in a post written shortly after the study’s publication:

Rather than looking for associations between individual variants and an observed trait, the researchers looked for associations between those variants and two latent traits: one representing genetic variance in cognitive performance (“Cog”), the other representing genetic variance in educational attainment that was independent of cognitive performance (“NonCog”). As the chart above shows, NonCog predicted socially effective personality traits (i.e., higher openness, conscientiousness, extraversion, agreeableness, emotional stability). These are the same ones we know from other research to be moderately associated with success in life. However, NonCog also predicted susceptibility to various mental illnesses.
Scott Alexander interpreted this as showing that these illnesses confer some kind of hidden benefit. I am more inclined to think that mentally ill people self-select into longer university educations. The jury is still out on which interpretation is correct. In any case, my point is that using the same reasoning, we can hypothesize that Indo-Europeans had some compensating non-cognitive traits that were key to them winning the demographic war over the farmers/hunter-gatherers ( they had mixed previously, with the farmers mostly winning).
Inferences about the direction of evolution (and the extent of corresponding group differences) can be challenged on the basis of potential bias in the training of the polygenic scores. These scores are exclusively trained on modern Europeans (mostly British people), so it is possible that they are afflicted by certain biases, notably ascertainment bias or uncorrected population stratification. The latter means that the model identifies some ancestry signal which predicts an outcome, not for genetic reasons, but rather because it serves as a proxy for some unmeasured environmental cause. The typical example is the use of chopsticks. If one did a GWAS on the use of chopsticks, the model would identify genetic variants that are common in Asian people, even though these don’t actually cause chopstick use in any kind of direct causal sense, but because they are proxies for being raised in an Asian culture.
One way to deal with the bias due to population stratification is to use results from more stringent GWASs. For instance, one can use those based on sibling pairs (the within family GWAS). Since sibling pairs have almost (but not entirely) the same ancestry, this design controls for most of the possible unmeasured environmental confounding if it indeed exists. Here are Reich and colleagues’ sibling GWAS results:

This figure is a little hard to interpret. The first three columns correspond to three different tests of polygenic selection; the fourth gives an estimate of SNP-based heritability; the fifth provides the sample sizes (with figures for the sibling GWAS in orange). As to the three selection tests, 𝛾 is just the change in the polygenic score, given in standard deviation units. 𝛾sign is the same, but using a potentially more robust version of the score. And rs is the speed of selection.
For those of us interested in the evolution of intelligence, we look at the rows with cognitive function and years of schooling. Note that since the sibling GWAS had quite a small sample size, it has little signal (see the detected heritability column). Naturally, when the scores are poor predictors, it is hard to find selection with them. Nevertheless, we see that of 3 + 3 tests for selection for education/intelligence, all 6 are positive, and 2/3 of the years of schooling sibling GWAS tests have p < .05 (if only marginally). Insofar as the sibling results are concerned, then, we can still see the selection signal (despite lower power owing to the lousy scores). There is also some evidence of selection for height, but it is less convincing, perhaps because the selection was weaker than for intelligence/education-related traits.
Another way to deal with population stratification bias is to use GWASs trained on an unrelated (that is, distant) population. As in previous studies, the relevant data come from the Japanese biobank. Here’s how the results based on the GWAS trained on Europeans compare to those based on the GWAS trained on East Asians:

The blue dot in the top corner, the phenotype with the strongest evidence of positive selection, is years of schooling, and this is true across all three selection tests. The agreement between the two datasets isn’t perfect (r’s = 0.41, 0.71, 0.85), of course, because the East Asian GWASs are much smaller than the European ones, so we expect a lot of random error. Plus, there are the effects of correcting for population stratification in the European GWASs. Yet, in the authors’ words, the consistency of the results is “very difficult to explain as an artifact of population structure”. Overall, there is strong evidence of natural selection for higher intelligence/education in West Eurasians over the last 14,000 years.
Geneticist Graham Coop has already posted a Twitter thread criticising the study. But in my view, he makes two mistakes. First, he ignores the results based on the GWAS trained on East Asians. Indeed, using the Japanese as an outgroup provides protection against bias due to population stratification, and yet the Japanese results were quite consistent with the European ones (as we saw above).
Coop’s second mistake is that he focusses on p-values, rather than actual estimates, when assessing the tests of polygenic selection. Since the sibling GWAS tests had such low power, owing to the small sample size, it is unwise to take p > .05 as evidence of no selection. Wiser is to look at whether the sibling GWAS results generally agree with the between-family GWAS results. Fortunately, the researchers provided the results in numerical form in their supplementary materials. And If we correlate the results across the two types of GWAS, we see that they are quite consistent:
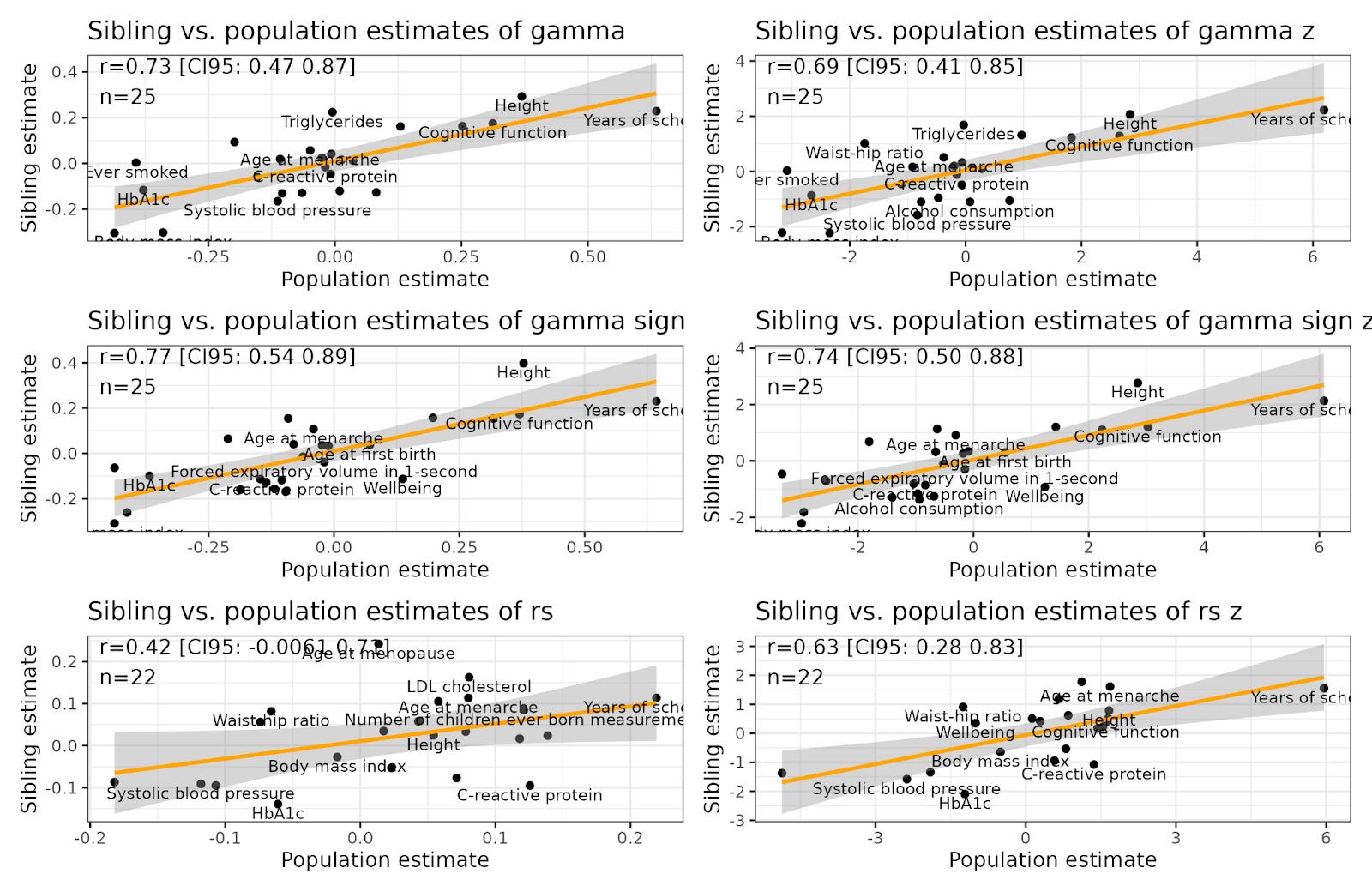
Taken together, the findings arguably vindicate the arguments put forward in Henry Harpending and Greg Cochran’s 2009 book, The 10,000 Year Explosion. As those two authors wrote, one could hypothesize that
West Eurasians have been experiencing qualitatively more and different natural selection in the Holocene than in earlier periods because of rapidly changing lifestyles and economies. Without a comparable time transect before the advent of food production and societies with high population densities, it is impossible to test this directly. However, this hypothesis is consistent with our evidence of particular intense selection for blood-immune-inflammatory traits, and our evidence that selection for these traits becoming even stronger in the Bronze Age than it was in earlier periods.
On this note, Reich’s team failed to cite certain prior research on the topic. Even though their paper has 220 references and runs to 53 pages (plus a 124 page supplement), the Harpending and Cochran book is not cited. Nor is our study from March of this year based on a partially overlapping dataset. Nor is the Yunus Kuijpers and colleagues study (which is also based on a partially overlapping dataset). Nor is the pioneering study by Michael Woodley and colleagues. Since we’re talking about a preprint, oversights of this sort can be forgiven. But one does wonder whether the authors made a deliberate attempt to avoid “stirring the pot” (while at the same time moving the Overton Window in line with Reich’s infamous New York Times article).
Emil O. W. Kirkegaard is a social geneticist. You can follow his work on Twitter/X and Substack.
Become a free or paid subscriber:

Like and comment below.
Thanks for an exciting and informative article on the expansion of West Eurasian cognitive ability over the previous 14 millennia.
What has always interested me is what caused the relatively fast expansion, other than the possibility of selection.
The study is great step forward. And I much expect that the many people who believe impossible things about human races will find five other impossible things to believe before breakfast.
One minor issue for me I expect is a bigger issue for Ali Akbari, whose name leads the list of 16 authors, whereas David Reich's name comes in dead last, following the pattern that a famous researcher's name gets tagged on at the end of a long list of coauthors even though he may know almost nothing about it, and yet David Reich has been getting effectively all the credit for this study (Steve Sailer had two Substack posts about this preprint recently).