


Written by Curmudgeon’s Corner.
Much has been written about artificial intelligence by computer scientists and experts in cognitive science. Here I take a psychometric perspective. Do the latest Large Language Models represent an unremarkable broadening of the abilities of traditional narrow AI? Or do they constitute a movement toward the goal of building “artificial general intelligence”, something analogous to human general intelligence? Let’s start by considering what actually qualifies as AGI.
American computer scientist John McCarthy coined the term “artificial intelligence” in 1956. The notion that machines could eventually achieve the same capacities as human intelligence is older still. Computer pioneer Alan Turing proposed his “imitation game” (more commonly known as the Turing Test). A computer system passes the test if it can trick a person into thinking that it is a fellow human being.
At the level of structure, AI systems do not resemble the human mind. They are exceedingly specialized, with source systems designed for narrow applications. These systems may spectacularly exceed human capabilities in their narrow domains. Think of IBM’s chess playing Deep Blue defeating Grand Master Garry Kasparov in 1997. Or the trivia-slinging Watson DeepQA beating the two all-time champions of the Q&A game show Jeopardy! (Brad Rutter and Ken Jennings) in 2011.
In response to Watson’s victory at Jeopardy! intelligence researcher Douglas Detterman issued the following challenge to IBM in the pages of the journal Intelligence:
Watson's Jeopardy victory raises the question of the similarity of artificial intelligence and human intelligence. Those of us who study human intelligence issue a challenge to the artificial intelligence community. We will construct a unique battery of tests for any computer that would provide an actual IQ score for the computer. This is the same challenge that humans face when they take an IQ test. The challenge has two levels. In the first, programmers could supply data and post hoc organizational algorithms to the computer. In the second, all algorithms would have to be provided before data are supplied and information would have to be self organizing as it is in humans.
At the core of Detterman’s challenge is a fundamental concept in the measurement of human intelligence, known as the principle of the indifference of the indicator. This principle, proposed by Charles Spearman in 1927, holds that the general factor in human cognitive test performance (g) is so ubiquitous that any task requiring cognitive work should measure it to some degree. Kasparov probably knew some trivia. Rutter and Jennings could probably play some chess or learn how. But try asking Deep Blue about trivia and then challenge Watson to a game of chess. The clear limits of these AI systems would then be obvious; the principle of the indifference of the indicator does not apply to them.
Today Deep Blue and Watson are called “narrow” AI. And narrow AI are considered a “weak” form of AI. Nonetheless, weak AI trained on natural language data arguably passes the Turing test routinely. This is apparent in the success of various AI-based social engineering scams.
The “strong” form of artificial intelligence is AGI, a term introduced by physicist Mark Gubrud in 1997. This form of AI would be able to mimic the human mind’s handling of “domain general problems”, which are those that require the agent to draw on content from whatever narrow domains are needed to solve a problem, and to combine that content in novel ways. Hence AGI entails the almost limitless versatility and context-independent quality of human problem-solving.
The ability to solve domain general problems is the essence of general intelligence, which is captured by the second level of Detterman’s challenge – the need for self-organization in the absence of algorithmic front-loading.
Talk of AGI was once limited to an incredibly niche bit of borderline sci-fi but is today prominently featured in major news media. It was after 2016 that interest really took off: between then and 2022, there was a 319% increase in Ngram impressions in literature (the Ngram database does not currently go beyond 2022).

With the popularization of LLMs – starting with the release of OpenAI’s Chat GPT-1 in November of 2022 – it is highly likely that interest in the concept of AGI has skyrocketed further in the last two years.
Debate rages about whether these newer LLMs (of which there are multiple generations and even phylogenies) qualify as AGI. Some of those who deny that LLMs have fully mature AGI wonder if they have a primitive form of AGI – a step on the path to the “Holy Grail” of true AGI. Others vigorously dispute this. They say that there are major differences between LLM and human problem-solving.
LLMs are notoriously dishonest. They present falsehoods as facts when asked to do something that, for whatever reason, they cannot do correctly. (Some may think this is akin to humans lying to conceal ignorance. But LLMs do not have motivations of this kind. They are simply programmed to provide responses to prompts that resemble certain responses to prompts on which they have been trained. Thus, when an accurate answer is not possible they provide something that looks like one.) Moreover they are known to fail at exceedingly simple tasks. And their performance across tasks is not consistent but strongly skewed in favor of certain domains.
This suggests that while they have forms of artificial expertise, they do not possess AGI. Perhaps an LLM can debug your code. But it may botch your legal briefs. This again shows that LLM “cognition” does not exhibit the principle of the indifference of the indicator – the key criterion of AGI.
I asked the world’s most famous LLM (ChatGPT-4) to evaluate its own abilities against Spearman’s principle of the indifference of the indicator. It doesn’t seem to “think” much of its performance, given that standard:
Prompt: Does your performance spectrum with respect to arbitrary tasks mirror Spearman's Principle of the Indifference of the indicator in the case of human general intelligence?
GPT-4: Spearman's Principle of the Indifference of the Indicator suggests that different measures of cognitive ability (indicators) should be equally good at reflecting general intelligence, as long as they are valid and reliable. This principle implies that general intelligence (g) should be consistent across various types of cognitive tasks.
In terms of how this principle relates to my performance, it’s a bit different. As an AI, my capabilities are based on how I was trained and the data I have been exposed to. My performance can vary widely depending on the specific task or domain. For some tasks, such as generating human-like text or answering factual questions, I might perform very well because these tasks align with the data I was trained on. For other tasks that require specialized knowledge or understanding of nuanced human experiences, my performance might be less reliable.
Unlike human general intelligence, which is thought to be a more general, unified capacity that influences performance across diverse cognitive tasks, my abilities are more task-specific. I don’t have a unified "intelligence" that spans all areas; rather, I have strengths and weaknesses based on my training and the algorithms that drive me.
So, while Spearman’s principle applies to human cognitive abilities suggesting a consistent level of general intelligence across different tasks, my performance does not mirror this principle directly because it is shaped by the nature of the tasks and the data I was trained on.
Applying psychometric methods to AI
Is there such a thing as “artificial general ability”? Maybe. But basic differences between LLM and human problem-solving still exist.
Recall Douglas Detterman’s challenge to the AI research community, which comprises two key elements. First: to pass as “intelligent” in the human sense, an AI needs to be able to deal with an arbitrary set of cognitive problems in much the same way as humans do when their intelligence is being assessed using standard psychometric tasks. Second: to achieve this, an AI must be capable of using its algorithms to solve such problems on an ad hoc basis.
Specifically, the algorithms should be able to produce solutions to any sort of problem without being trained on any specific dataset. This is analogous to Spearman’s principle of the indifference of the indicator – the idea that any arbitrary set of cognitive tasks should produce a good representation of the g factor. (The g factor participates in problem-solving whenever there is a cognitive component present, irrespective of the task.) If AIs were to meet Detterman’s challenge, it would be essential that their performance be indifferent with respect to whichever set of indicators is used to evaluate their performance.
Engagement with Detterman’s challenge within the AI research community has been limited. His paper has racked up a paltry 39 citations over the last 13 years. This is not to deny that there has been some engagement. AI researchers David Dowe and José Hernández-Orallo addressed it directly in the pages of the journal Intelligence in 2012. They noted that:
Complex, but specific, tasks—such as chess or Jeopardy!—are popularly seen as milestones for artificial intelligence (AI). However, they are not appropriate for evaluating the intelligence of machines or measuring the progress in AI.
And they went on to observe that relatively simple systems can “pass” IQ tests. Detterman’s challenge “may not be so demanding and may just work as a sophisticated CAPTCHA, since some types of tests might be easier than others for the current state of AI.” Indeed, just because some classes of IQ test can be broken down into algorithmically solvable components does not mean that machines capable of doing this are using the same sorts of processes as humans.
Detterman’s challenge implies an additional intriguing prediction, even if Detterman did not spell it out. Given a population of AIs that satisfy the conditions of the challenge and that also vary in “ability”, it should be possible to extract a general factor of performance akin to Spearman’s g. And in fact, a new paper in Intelligence by David Ilić and Gilles Gignac has investigated this possibility:
Based on a sample of 591 LLMs and scores from 12 tests aligned with fluid reasoning (Gf), domain-specific knowledge (Gkn), reading/writing (Grw), and quantitative knowledge (Gq), we found strong empirical evidence for a positive manifold and a general factor of ability. Additionally, we identified a combined Gkn/Grw group-level factor.
Their data fit a “bi-factor model”. These are models that represent g as a “breadth factor”, with narrower abilities competing for variance. Hence they assume no hierarchical relationship between g and those narrower abilities. This is depicted in Ilić and Gignac’s Figure 1:
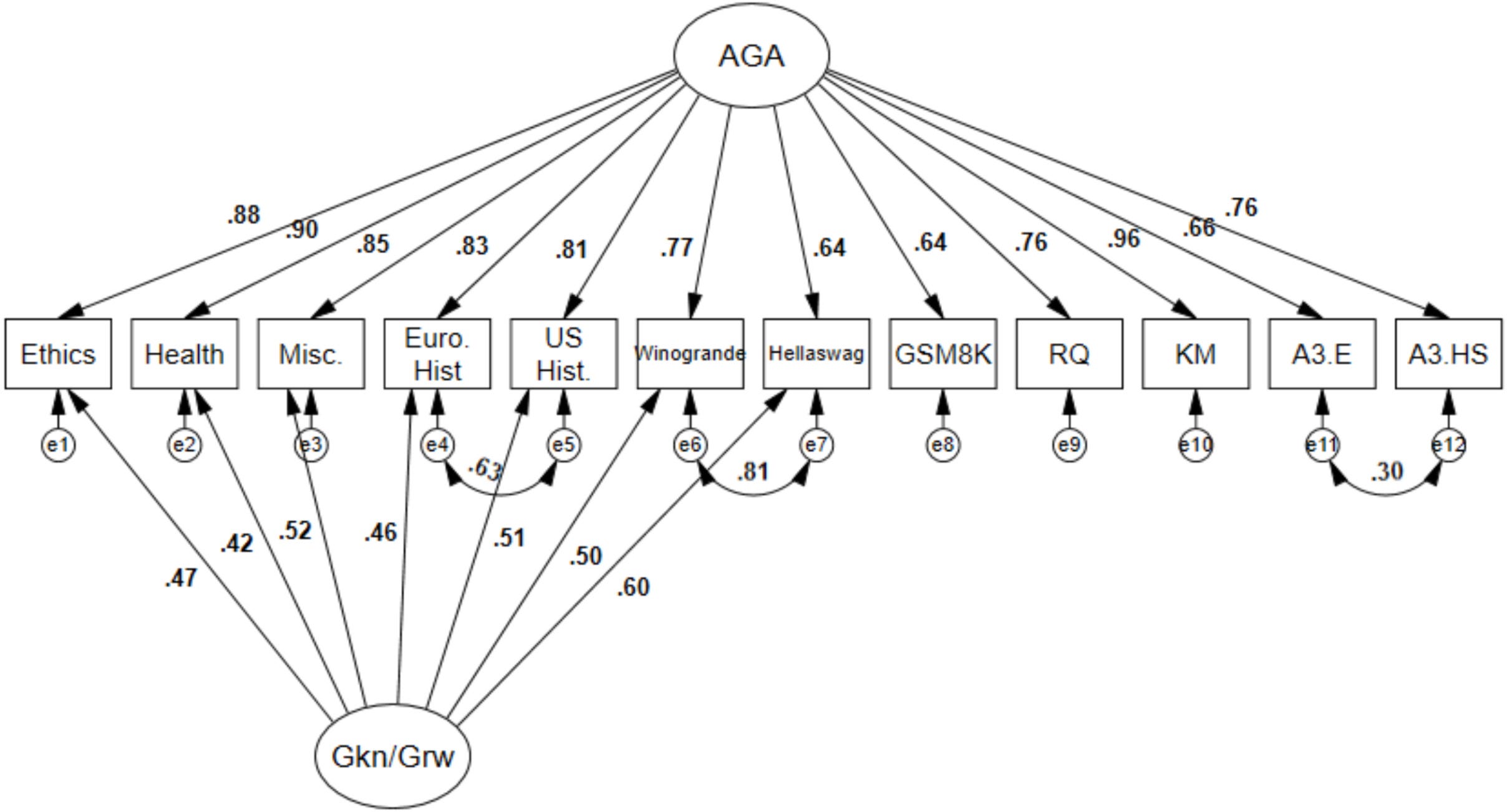
The g factor in their case is termed artificial general ability. The arrows going from the AGA factor to the specific indicators correspond to specific problem types that the LLMs in their “population” had to solve. These are all positive – so the LLMs that perform better with respect to one task set also tend to perform better with respect to other tasks. And vice versa in the case of poorer performance.
The domain specific knowledge and reading/writing performance formed its own unique group factor. The group factor contributes to performance in a subset of seven tests independent of the AGA factor. The curved arrows are termed correlated errors. These capture unmodeled sources of covariance among abilities. They are often needed to fine tune models like this, but you needn’t worry about them.
So it looks like LLMs might have something we can liken to human general intelligence after all. However, these authors cautiously note that, “While our findings suggest the presence of a general factor of ability in LLMs, it is unclear whether this factor represents true artificial general intelligence or merely artificial general achievement.”
They are candid in acknowledging limitations: “Given the nature of LLM development and training, and the essential need for novelty in intelligence testing, there may be more evidence supporting artificial achievement/expertise than artificial intelligence.”
The critical question therefore becomes: is the ability to isolate an AGA factor from among a performance-heterogeneous LLM population sufficient evidence of AGI?
As Ilić and Gignac note, LLMs are heavily dependent on training data. Such data can vary both in terms of quality and quantity, which makes it one possible cause of both inter-LLM performance variance and covariance. Having a poorer quality training dataset should throttle LLM performance on any sets of tasks that draw on common processes that have ultimately been trained on that dataset. The use of training data, in addition to other limiting factors, imposes additional generalizability limits on the systems. High generalizability in the form of ability to competently solve a large array of problems (owing to a broad training database) does not mean that the principle of the indifference of the indicator has really been satisfied.
Humans are indifferent to cognitive context so that g factors emerge in almost any set of cognitive tasks given them. Whatever process lies behind this empirical regularity is likely very different from the process that gives rise to AGA.
In my opinion, Ilić and Gignac hit the proverbial nail on the head in making the following cautious observation in their paper: “Some argue that true intelligence includes self-awareness and the capacity for autonomous improvement through self-evaluation.” These qualities are yet to feature in AI.
Is it possible to show that the way humans perform on an IQ test is different from the way AI performs when administered the same test? The blogger Crémieux Recueil conducted a very interesting study on this topic, using a figural matrices test. These tests, such as the famous Raven’s, require the test-taker to identify a pattern in a matrix or grid. Think of this like a puzzle. You have to say which of several pieces corresponds to the missing part of a pattern. An example item from Wikipedia is depicted below.

It turns out that the ability to solve figural matrices tests can be reduced to just a handful of simple rules: scan horizontally, vertically, diagonally; look for repeated, deleted, inserted elements, etc. When used in combination, these rules are sufficient for solving pretty much any item in the Raven’s test series. So an LLM that identifies these rules should be able to solve them – and indeed they can.
The question, if you recall, however, is not whether AI systems can be made to simulate human performance on IQ tests. It is whether or not this is how humans actually go about solving these tests when first confronted with them.
Crémieux used a measurement invariance approach. Measurement invariance simply denotes whether the same construct is being measured in different groups of test-takers. Cremieux compared the performance of four human groups, who had received different degrees of training on a set of figural reasoning items, with the performance on these items of one LLM: Claude 3 Opus. Cremieux describes his comparison model as follows:
So to hint at the comparability of human and LLM performance, I correlated the percentages correct for each item from the original study’s four different groups with the percentages correct from Claude’s assessment, like so:

As Cremieux observes:
When human groups with different levels of training in figural matrix rules got questions correct, so too did the other groups. But Claude’s performance was essentially random with respect to the human groups. Different individuals’ performances were also correlated with the performances of other individuals, consistent with the common usage of strategies across individuals leading to common patterns of performance or, more simply, that questions vary in their difficulty, so there are some that more people tend to get right, and those questions are not the ones that LLMs tend to get right.
More intelligent humans tend to use strategies to answer questions which are consistent with success in answering and correlated in usage across questions. There doesn’t seem to be any evidence that Claude uses the strategies humans do so, at the very least, we have no a priori reason to believe Claude’s reasoning is driven by the same construct driving reasoning in humans.
The fact that the LLM is not exhibiting the same performance pattern as the human participants (who appear to be using common strategies) suggests that the LLM uses different strategies. One speculative possibility is the previously mentioned rule-reliance of figural reasoning items. Humans can abstract the existence of such rules while lacking any prior knowledge of them. An LLM has access to a large training set already containing these rules, on the other hand, and just has to efficiently locate them (via a sort of pattern matching) in order to exploit them.
LLMs can well mimic general intelligence when faced with certain tasks – but it is not the real deal.
The risks of AGA
Does artificial general ability poses an existential threat, or any other kind of risk, to mankind? In 2002, the ethicist Nick Bostrom defined an existential risk as “one that threatens the premature extinction of Earth-originating intelligent life or the permanent and drastic destruction of its potential for desirable future development”.
Decision theorist Eliezer Yudkowski believes that AI is likely the biggest existential risk of all. According to him, all work on the matter should be halted immediately. Mincing no words in a Time article from 2023, he states the following:
Many researchers steeped in these issues, including myself, expect that the most likely result of building a superhumanly smart AI, under anything remotely like the current circumstances, is that literally everyone on Earth will die.
He is not alone in this belief. A petition that has racked up nearly 34,000 signatures (as of this writing) calls on all AI labs to “immediately pause for at least 6 months the training of AI systems more powerful than GPT-4”.
The precise nature of this danger is never adequately explained. Vague claims are made in the petition that more powerful LLMs “pose a profound risk” and that they could “represent a profound change in the history of life on Earth.” Ultimately, these concerns seem to boil down to the idea that because humans can do enormously destructive things with their g – AIs with vastly greater intelligence could be orders of magnitude more destructive. Some have expressed concern that such AIs may attempt instrumental convergence where end goals are never satisfied. One famous example of this is the “paper-clipper”, a hypothetical AI that is tasked with the continual manufacture of paperclips, and which pursues ever more exotic ways of getting hold of the necessary raw materials (e.g., sending rockets to asteroids to mine the iron necessary for its “mission”).
As I argued above, current manifestations of AI such as LLMs don’t qualify as AGI. They cannot solve domain general or open-ended problems. In other words, AGI would need to be able to solve any kind of problem in approximately the same way as a human – via the application of general intelligence.
We now know that a population of LLMs can conjure up a simulacrum of g (euphemistically called “artificial general ability”). But the way in which the systems go about “solving problems” does not resemble the way in which humans go about solving the same problems. As Crémieux Recueil notes, the evidence doesn’t support the all-important requirement of measurement invariance. This means that humans and machines are still worlds apart in terms of their capabilities.
Let me illustrate with a simple analogy. A rocket and a balloon both seem at one level to be doing the same thing (that is, flying). There are parallels between how the two machines work (both generate forces to counteract the pull of gravity). But that is where the similarity ends. Buoyancy caused by lighter-than-air gases may get you stuck in a tall tree but it will not put you into orbit – let alone to the moon. Rocket thrust on the other hand will. Or to put it another way, LLMs give lethal culinary advice, whereas a human gourmand can cook prize-winning meals.
An interesting question that few seem to ask is: if a real AGI were to exist, why would it be dangerous? Even assuming the system were given malign motives (for example, paper-clipping), the task of learning is hard; fully g-equipped humans will go to great lengths to avoid having to do it. Anyone who has had experience at either end of the K-12 education system knows this. As the futurist and YouTuber Isaac Arthur1 has noted:
Suppose you have a hypothetical AI super intelligence and you task it with solving problems. Would it be possible that the AI decide to slack off or develop bad habits, not doing the required work, etc?
The fretting of modern elite opinion-formers over AI mirrors that of their counterparts in the 2000s. Back then they worried about so-called nanotechnology. It seems doubtful that anything truly disruptive – let alone on the order of an existential risk – will emerge from current advances in AI. Anyone remember when King Charles III told us that we were all going to be turned into puddles of grey goo by nanites running amok? All we got instead were tiny carbon nanotubes that nobody can figure out a use for (I’ll bet they are wildly carcinogenic though).
My favorite internet curmudgeon Physicist and blogger Scott Locklin has a few choice words for LLMs:
We’re again going through such a mass hysteria, with featherheads thinking LLMs are sentient because they’re more interesting to talk to than their redditor friends. The contemporary LLMs being a sort of language model of the ultimate redditor. People think this despite the fact that since the 2010-2015 AI flip out which everyone has already forgotten about, there hasn’t been a single new profitable company whose business depends on “AI.” It’s been over 10 years now: if “AI” were so all fired useful, there would be more examples of it being used profitably.
For AI, we have arguably reached the point in Gartner’s Hype Cycle known as the “peak of inflated expectations”. The media endlessly chatter on about self-driving cars and how LLMs will make human jobs obsolete. They prattle interminably about the “dangers” of super-human AI without actually explaining exactly what is entailed here. Just give it two to five years, however, and we will be in the "trough of disillusionment”. Maybe in 10-15 years we will have reached the “plateau of productivity” for LLMs. Then we will all look back on today’s hype, and will regard the current peddlers of LLM hysteria in much the same way as sane people do today the predictions of Paul Ehrlich – the most consistently incorrect man who ever lived (that takes actual talent believe it or not).

Your LLM is unlikely to suddenly come alive and start exhibiting an unhealthy interest in paperclips. But there are ways in which these technologies could and indeed will make ordinary people’s lives (just a bit more) miserable. There is the ability to manufacture deepfakes – images and footage so realistic that you would swear that it was you in that bed with that hooker. (The give-away is the number of fingers, usually.)
The mischief that these can cause is incalculable. One possibility involves injecting fake news into an already febrile media. The opportunities for creating new forms of blackmail seem almost limitless. Improvements in behavioral modeling might allow for some kind of pre-crime system to emerge. Insufficiently lobotomized LLMs may actually explain to you how to construct bombs. There is even evidence that LLMs are succumbing to some kind of an AI equivalent of the “reverse Flynn Effect”. The outputs of more recent versions of Chat GPT having apparently become objectively worse with time.
This is just the tip of the iceberg, of course. There are surely many unforeseen ways in which LLMs will make things worse. They may also improve life a bit. Certain classes of job are sufficiently dull and simple that they can probably be done better by LLMs already (and who wants to work these jobs anyway?) I would add to that list schoolteachers. It is likely that LLMs would do a better job of educating kids – or to put it another way they are unlikely to do a worse job.
Conceivably responsible use of LLMs could help mitigate some real problems – such as poverty. And there is always the possibility that they could enhance the scientific research process – perhaps by allowing us to finally get rid of professional coders.
I began this essay by considering whether LLMs might pass Detterman’s challenge, and concluded that they are unlikely to satisfy its key component – the principle of the indifference of the indicator. (Even Chat GPT-4 seems to agree on this point!) I then examined LLM performance in relation to psychometric benchmarks. A recent paper showing the existence of an artificial general achievement factor at first glance suggests that something akin to AGI can be found in the performance differences within a “population” of LLMs. However, on closer inspection it appears that at the level of specific tests, LLM and human performance is quite distinct: while the latter make use of common factors in solving these items, the former do not. It is possible that LLMs are instead merely good at locating the appropriate rules in their training databases and applying them efficiently. Finally, I considered the risks associated with AGI and the current crop of LLMs. Whilst there could be risks associated with real AGI, LLMs do not qualify as such. LLMs may create other (non-existential) risks, however, such as increasing the efficiency of a surveillance state and generally making people’s lives miserable through deepfakes and blackmail. (Some good may come from their sensible application too.)
On a closing note: although my background is in psychometrics, I have been keenly following developments in AI since I first read Detterman’s 2011 paper. Recent use of psychometric methods on LLM populations has impressed me greatly. Further developments involving measurement invariance models (along the lines proposed by Crémieux) should be a major goal for those who work in AI and human intelligence. It is through the use of these models that we will get a sense of whether real progress is being made toward AGI.
Curmudgeon’s Corner is the pseudonym of a writer with interests in AI and human intelligence.
Consider supporting Aporia with a paid subscription:

You can also follow us on Twitter.
For those of you who don’t know of his work, do check out his excellent and thought-provoking YouTube channel. When I have on occasion posed Arthur’s question to AI experts it is usually met with a glassy stare. Apparently, it is just not something that they think all that much about. So Yudkowski can (probably) relax.
Interesting stuff!
"Some have expressed concern that such AIs may attempt instrumental convergence where end goals are never satisfied."
This phrasing I think demonstrates a lack of understanding of the concept. As I understand it, it's simply the observation that some things are useful as means to a wide range of ends. Money, for example. If I ask whether some random person would like to have a large sum money, you can confidently answer that they almost certainly will. How can you know that without knowing anything about their history, genetics, personality, goals, hopes, fears, etc? Because with extraordinarily few exceptions, everyone wants SOMETHING, and money can be useful in the attempt to get virtually anything. Even less "materialistic" desires like enlightenment...you could hire a guru/personal meditation tutor. Feeling that you did good--give to charitable causes. Etc. Etc.
So anything that is a rational agent, that has goals and the ability to understand what money is and how to use it, will probably want money. What else can we be confident it will want, knowing only that it is a rational agent? Resources generally, basically the same as money. It will want to not die, because no matter what your goals are, it's harder to accomplish them if you're dead. Similarly, it will not want its goals to be changed...because that would make its goals less likely to come to fruition. (Imagine being offered a pill that would make you want to kill your child/spouse/pet. It would also make you have no remorse and in fact be intensely satisfied by doing it. Would you take the pill?) It will want to improve itself/make itself smarter/more powerful, because that would make it easier to achieve its goals, no matter what they are.
So just starting with the premise that it is a rational agent, we can be confident that there are several characteristics/desires that it will almost certainly have:
- will want to accumulate resources
- will resist being "killed"/shut off
- will resist being reprogrammed
- will attempt to improve itself
It's not hard to see how this could turn out to be problematic, unless we can figure out how to make sure its ultimate goals will cause it to seek outcomes that we would regard as desirable, ie the problem of "alignment".
But you're right that LLMs don't qualify as AGI in the above sense that we would need to worry about. I think the key reason is not that they are not intelligent enough or that their intelligence is not general enough, but that they are not agents. It doesn't matter how smart their answers are; they are never going to do anything unless you type into their prompt. In which case, they will respond with a single block of text. Their design doesn't seem to make it possible for them to do anything else. And they don't sit around plotting and strategizing in the meantime.
Could LLMs be turned into agents? I don't understand the technology well enough to comment on this meaningfully, but I'd say...in their current form, there is no way they could simply become agents, but could the technology be re-worked to turn them into an agent? Given the spectacular success and rate of improvement of LLMs, it seems entirely plausible that an actual, agentic AGI could be a real thing in the near future. Pretty sure some people are working on it. Others would know more about that me.
I'm not an AI doomer; I think the technology is amazing, and...I think I might want to see it go forward even if I did genuinely think there was a risk of human extinction. The thought of humanity just stagnating and carrying on as always until an asteroid hits seems even more depressing to me. Not that those are the only two options. Point is, I'm not super-terrified about it, but the arguments about the potential risks of AGI seem very straightforward and sound, and in fact are taken seriously by many legitimate experts in AI, so to just glibly dismiss them is I think, just...glib.
Here are a few reasons to (not) take AI risk seriously: https://youtu.be/9i1WlcCudpU?si=3MHcuXD3xYls5Bfv
What happened to the recent discussion on 'The Future of Genetic Engineering'? I can no longer access the opinions page.